Locust alternative: a worked locustfile.py migration
If you're searching for a Locust alternative, you probably already have a locustfile.py. This guide takes a real one, translates it to LoadTester, and points out the cases where the translation is clean — and the cases where you should stay on Locust because Python is exactly the right tool for the job.
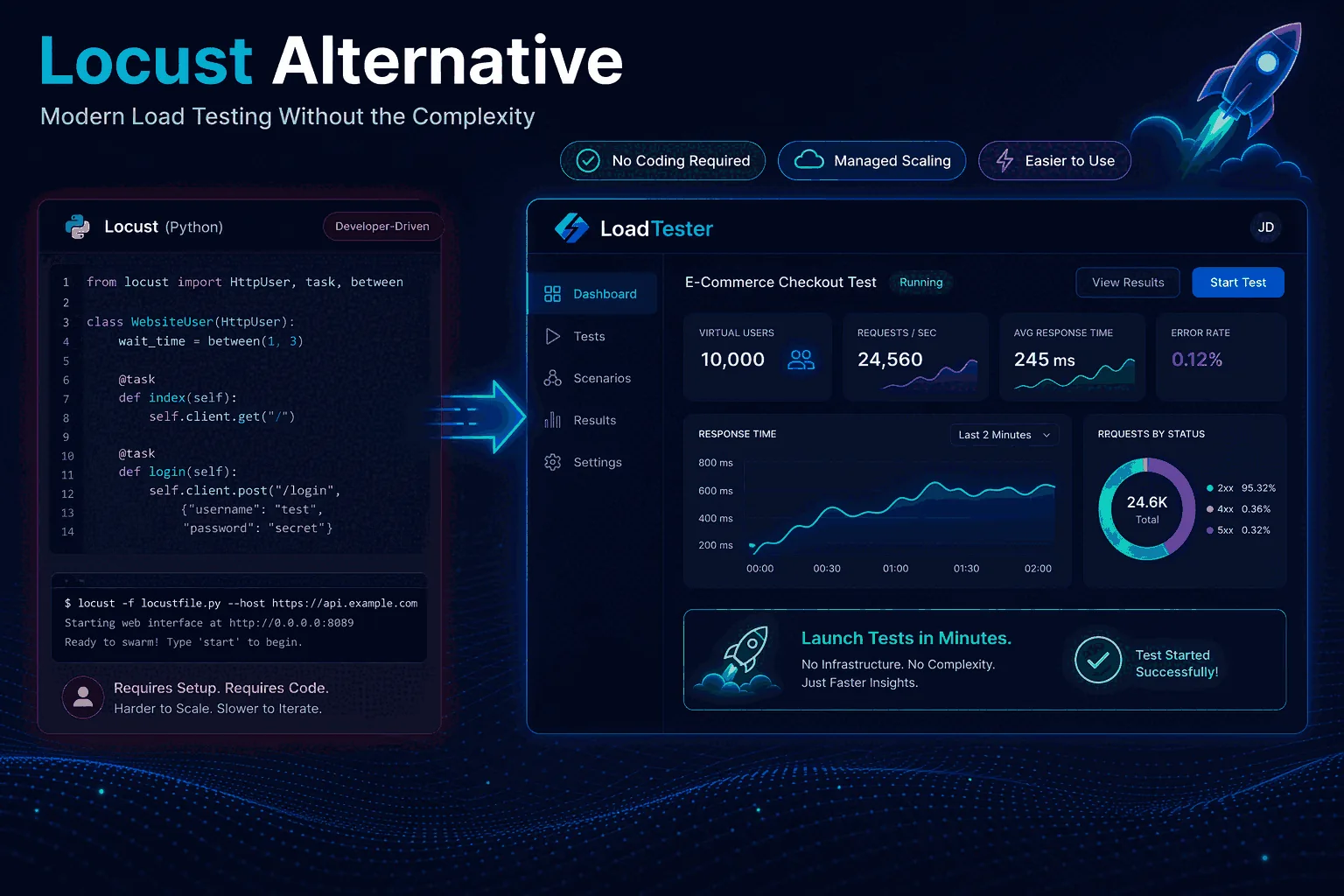
Quick verdict
The Locust decision usually depends on whether Python behavior modeling is a strength or unnecessary overhead. LoadTester is better for standard HTTP/API checks where the hard part is repeatability, reporting, and team visibility.
The starting point: a real locustfile.py
Here's a Locust file that simulates an authenticated checkout flow with browse-then-buy behavior:
from locust import HttpUser, task, between
import json, random
class CheckoutUser(HttpUser):
wait_time = between(1, 3)
def on_start(self):
r = self.client.post(
"/api/auth",
json={"email": "test@example.com", "password": "test"},
)
self.token = r.json()["token"]
self.client.headers["Authorization"] = f"Bearer {self.token}"
@task(3)
def browse(self):
self.client.get("/api/products?category=shoes")
@task(1)
def checkout(self):
sku = random.choice(["SKU-1", "SKU-2", "SKU-3"])
with self.client.post(
"/api/checkout",
json={"sku": sku, "qty": 1},
catch_response=True,
) as response:
if response.status_code != 200:
response.failure(f"checkout failed: {response.status_code}")
Run with: locust -f locustfile.py --users 200 --spawn-rate 10 --run-time 60s --headless.
Three things make this Locust-shaped: the HttpUser class, weighted @task decorators (browse runs 3× as often as checkout), and Python control flow inside the task. We need all three to translate.
The translation, step by step
Step 1: Auth as a setup request
Locust's on_start runs once per virtual user before tasks begin. In LoadTester, this is a setup request on the scenario — same intent, different name. The token is captured into a scenario variable from the response body using a JSONPath extractor:
Setup request:
POST {{base_url}}/api/auth
Body: {"email":"test@example.com","password":"test"}
Capture: $.token -> scenario variable: token
That variable is then referenced as {{token}} in subsequent request headers — equivalent to Python's self.client.headers["Authorization"] = ....
Step 2: Weighted tasks become weighted scenario steps
The @task(3) / @task(1) decorators in Locust express a 3:1 ratio. LoadTester scenarios support the same via step weights:
Step "browse" weight: 3
GET {{base_url}}/api/products?category=shoes
Header: Authorization: Bearer {{token}}
Step "checkout" weight: 1
POST {{base_url}}/api/checkout
Header: Authorization: Bearer {{token}}
Body: {"sku":"{{sku}}","qty":1}
Assert: status == 200
The 3:1 ratio is preserved exactly. The between(1, 3) wait time becomes a think time field on the scenario.
Step 3: Random SKU selection — where it gets interesting
This is the part that doesn't translate cleanly. Locust uses random.choice(["SKU-1", "SKU-2", "SKU-3"]) — arbitrary Python. LoadTester offers two patterns:
- CSV data source. Upload a CSV with a
skucolumn; LoadTester picks rows round-robin or randomly per VU. Cleanest for parameterization. - Built-in random helpers. Templates support
{{random_choice(SKU-1,SKU-2,SKU-3)}}for inline cases.
For more complex per-request logic — derived signatures, computed timestamps, anything that genuinely requires a programming language — see the "When to stay on Locust" section below.
Step 4: catch_response → assertions
Locust's catch_response=True with manual response.failure() becomes a response assertion on the LoadTester step: status == 200. For non-trivial validation (e.g., "response body must contain order_id and total > 0"), LoadTester supports JSONPath assertions and regex matchers covering the common cases.
Feature parity matrix
Honest checkmarks. ✓ = full parity, ◐ = partial parity, ✗ = not supported in LoadTester.
| Capability | Locust | LoadTester |
|---|---|---|
| HTTP/HTTPS load generation | ✓ | ✓ |
| Weighted tasks | ✓ | ✓ |
| Per-VU setup (on_start) | ✓ | ✓ |
| Variable capture from response | ✓ (Python) | ✓ (JSONPath, regex, headers) |
| Wait time between requests | ✓ | ✓ |
| CSV-based parameterization | ◐ (manual) | ✓ (built-in) |
| Arbitrary Python in tasks | ✓ | ✗ |
| Custom event hooks (request/spawn/quitting) | ✓ | ◐ (webhooks at run boundaries only) |
| Distributed workers | ✓ (you operate them) | ✓ (managed) |
| Real-time web UI | ✓ (local) | ✓ (cloud) |
| Run history and comparisons | ✗ (CSV exports) | ✓ |
| CI/CD via API | ◐ (CLI exit codes) | ✓ (REST API) |
| Custom load shapes (LoadTestShape) | ✓ | ◐ (presets + ramp/hold/decline) |
| Non-HTTP protocols (gRPC, WebSocket) | ◐ (community libs) | ✗ (HTTP-focused) |
When to stay on Locust (and not migrate)
Three concrete cases where Locust is the better tool and this whole article doesn't apply to you:
- Your test logic is genuinely Python-shaped. If you're computing HMAC signatures from request bodies, decoding protobuf to make assertions, or driving the test from a Pandas DataFrame — Locust is exactly right. The alternative isn't migration, it's keeping Locust.
- You need custom event hooks deep in the request lifecycle. Locust's
events.request,events.spawning_complete, etc. let you wire arbitrary instrumentation. LoadTester has webhooks at the run level but not per-request. - You have a non-HTTP target. Locust's community library covers gRPC, WebSocket, and custom transports. LoadTester is HTTP/HTTPS only.
If any of these describe your test plan: don't migrate. The wrong reason to switch is brand consistency; the right reason is workflow fit.
A 30-day migration plan (if you decide to switch)
Don't do a big-bang migration. The pattern that works:
- Days 1–7. Pick one Locust test that's been the most maintenance pain. Recreate it in LoadTester using the translation steps above. Run both side by side. Confirm the numbers agree within noise.
- Days 8–14. Wire it into one CI pipeline as a release gate. Get the team comfortable with the run page, share links, comparison view.
- Days 15–21. Migrate the next 2–3 tests. By now the translation is mechanical.
- Days 22–30. Decide which Locust tests stay (the Python-shaped ones from the previous section) and which to port. Document the split.
Most teams end up keeping 10–30% of their Locust tests for the cases where Python is genuinely the right tool, and moving the rest to LoadTester for routine HTTP and API work.
How this comparison was evaluated
For this Locust alternative page, we evaluated the difference between Python-modeled user behavior and managed HTTP/API regression checks. Criteria included scenario complexity, data generation, worker orchestration, CI usage, result storage, run comparison, and team readability.
Locust is the better tool when Python is the natural expression for the workload. LoadTester is the better fit when the scenario is a standard API path and the organization wants less code and less infrastructure around every run.
When Locust is the right tool
- Your team is Python-first and you want
locustfile.pyin the same repo asmanage.pyor your FastAPI app. - You're modeling user behavior with custom Python logic that benefits from the full library ecosystem.
- You need a free, MIT-licensed, fully self-hosted tool with no SaaS dependency.
FAQ
Why do teams move from Locust?
Usually not because of Locust itself but because of the surrounding workflow — managing distributed workers, building dashboards, sharing results with non-Python people, and keeping the testing practice alive across the team.
Is Locust still the right choice for Python-heavy organizations?
For tests that are genuinely Python-shaped, yes. For routine HTTP and API checks, the language match isn't worth the operational overhead in most cases.
How do I run both side by side during migration?
Run them against the same target with the same VU count and duration. Compare p95 and error rate; they should agree within a few percent. Any large discrepancy usually means the parameterization differs, not that one tool is faster.