Artillery.io Alternative
Quick verdict
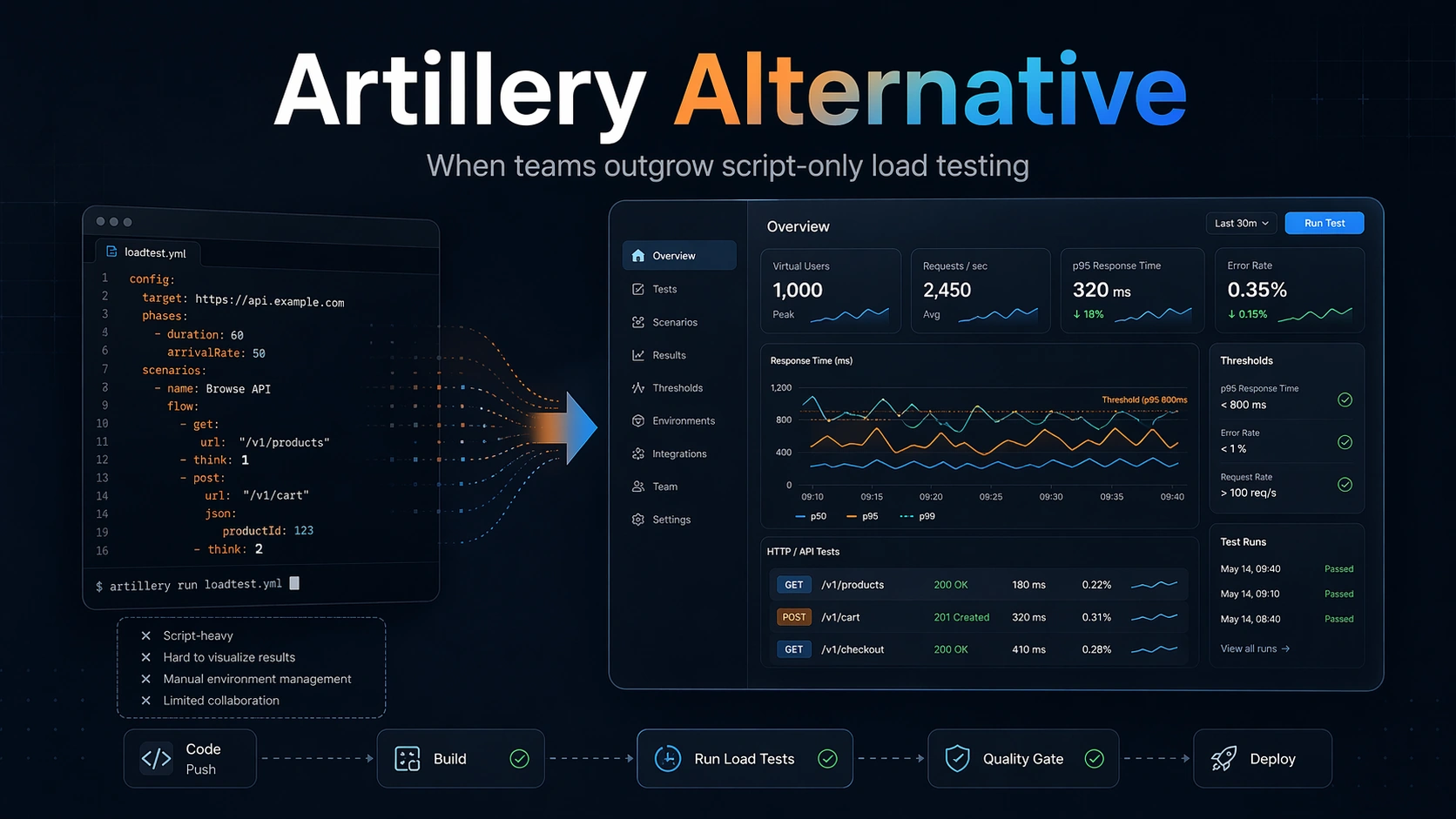
The decision is less about whether YAML or a hosted UI can send traffic and more about who will maintain the workflow. Artillery favors developer-owned configuration; LoadTester favors repeatable checks that QA, product, and engineering managers can also inspect.
Why teams adopt Artillery in the first place
Artillery's appeal is straightforward. YAML scenarios live in the repo next to the application code, get reviewed in pull requests, and run from the same CI runner as everything else. JavaScript hooks fill in the gaps the YAML can't express. For a backend engineer who needs to load-test an endpoint without leaving their editor, it's well-designed.
Those are creation-time advantages. They get you to the first run quickly. They don't address the lifecycle questions that show up around test number ten: who owns the baseline, how do you tell whether today's p95 is a regression from last week's, who reads the result when the engineer who wrote it is on PTO. That's where the search for alternatives starts.
Why teams start looking for an Artillery.io alternative
Teams don't abandon Artillery for a single fatal flaw. They outgrow it through accumulation: an SRE adds custom reporting, a DevOps engineer writes the CI integration, someone else builds a comparison script, and a year later you have a Rube Goldberg of glue around a tool that originally fit in twelve lines of YAML.
The four specific pain points that drive the alternative search:
- Repeatability. Same YAML, different runners, different env vars, different baseline numbers. The variance is real but invisible until you start trusting comparisons.
- Interpretation. Terminal output is fine for the test's author. PMs, on-call reviewers, and release managers need a result page, not a JSON dump.
- CI semantics. Anything is automatable in theory. In practice, custom shell parsers around
artillery reportoutput start failing the moment the format changes or the maintainer leaves. - Adoption. Teams say they want code-only tooling. What they actually want is a workflow more than one person can operate. Those aren't the same thing.
What a better alternative should improve
A serious alternative should not be judged only on language preference. Whether the scenario is written in YAML, JavaScript, or a web UI is secondary. From an operational standpoint, the better tool is the one that makes the full lifecycle of performance testing easier to run and easier to trust.
First, it should improve baseline handling. Teams need a clean way to compare the current release candidate with a known-good build or an expected performance envelope. Absolute numbers by themselves are rarely enough. A p95 of 420 ms may be fine on one service and a regression on another. Context matters. Good tooling makes those comparisons explicit rather than leaving them to manual memory or ad hoc spreadsheets.
Second, it should improve thresholds and failure semantics. A pass or fail should mean something precise. For example, p95 under 450 ms, error rate under 0.5 percent, sustained request rate above a minimum threshold, and no timeout burst longer than a specific duration. These conditions should be easy to define, easy to review, and easy to enforce in automation. Teams should not have to reverse-engineer whether a run was acceptable.
Third, it should improve shareability. An engineer should be able to send one link or one report to another engineer and have the result understood quickly. This sounds mundane, but it is one of the highest leverage improvements in practice. If every discussion starts with “let me explain how I ran it,” the workflow does not scale.
Fourth, it should improve environment discipline. Mature load testing is about controlled experiments, not just traffic generation. Which dataset did you use? Which environment? Which build? What concurrency shape? Were the downstream services enabled? What warm-up happened? A better alternative records and surfaces these details so runs are comparable.
Fifth, it should reduce glue code. The more custom shell scripts, parsers, log scrapers, and exporter fragments your team needs just to make a test useful, the less confidence you should have that the workflow will survive organizational change. An alternative that collapses that glue into native features usually wins over time because it reduces failure modes outside the system under test.
Artillery vs modern workflow platforms
The cleanest way to frame the comparison is this: Artillery is primarily a test authoring and execution tool, while a modern workflow platform is a release-quality system for repeatable performance validation. Those categories overlap, but they optimize for different jobs.
If your team is mostly solving “how do we model traffic?” then Artillery can be enough. If your team is solving “how do we operationalize performance checks across repos, environments, releases, and people?” then authoring is only one small piece of the puzzle. The operational surface becomes more important than the scripting surface.
In day-to-day DevOps work, this difference shows up everywhere. A CLI-first tool often assumes the engineer will assemble context around the run: collect artifacts, archive results, compare historical data, and make the pass/fail logic visible to the rest of the delivery pipeline. A workflow platform tries to treat those concerns as first-class: test history, thresholds, comparisons, shareable output, stable execution, and repeat runs across environments.
That does not mean platforms magically remove engineering judgment. You still need to design meaningful scenarios, isolate noise, understand workload shape, and know your service architecture. But a good platform reduces the amount of bespoke operational plumbing your team has to own. That trade-off matters especially for SRE teams whose time is better spent improving system reliability than maintaining the scaffolding around a test runner.
For many organizations, the choice is not between open source and managed in the abstract. It is between paying the operational cost explicitly in platform fees or paying it implicitly in engineer time, inconsistent process, slower release reviews, and weak reliability signals. Once you count the real cost of the second option, the decision becomes less ideological and more practical.
When Artillery is still the right tool
There are absolutely cases where staying on Artillery is the right call. If a single team owns the service, the load tests are used mostly for engineering exploration, and the readers of the output are the same people who wrote the scenarios, the workflow burden may stay small enough to be acceptable.
Artillery also makes sense when the organization values script portability more than process standardization. Some platform teams prefer to keep everything in the repo and are willing to invest in their own wrappers, historical storage, and reporting conventions. If that internal platform work is intentional, staffed, and reusable across teams, then the trade-off can be justified.
It can also be the right fit for targeted diagnostic work. During an incident review or a pre-optimization experiment, an SRE may want a quick test harness rather than a long-lived performance program. In those moments, speed of authorship can matter more than polish of lifecycle management.
The key is honesty about scope. Problems appear when organizations use Artillery as if it were already a release-quality platform without funding the extra workflow around it. That is the danger zone. If you keep Artillery, keep it for the cases where its strengths are actually aligned with the job: developer-led experiments, contained ownership, and relatively lightweight collaboration requirements.
In other words, do not switch tools just because a comparison page tells you to. Switch when the process around the tool has become the bigger problem than the test definitions themselves.
When LoadTester is the better Artillery alternative
LoadTester becomes the better Artillery alternative when your performance testing program has crossed from ad hoc engineering checks into operational decision support. That usually happens earlier than teams expect. The first signal is that test results are being discussed in release meetings. The second is that on-call or platform engineers need to trust the runs without reproducing them manually. The third is that a regression in latency or error rate should block a deployment rather than merely generate a conversation.
From that point on, workflow features stop being cosmetic. Historical comparisons matter because today’s latency only has meaning relative to yesterday’s baseline. Thresholds matter because CI/CD needs deterministic pass/fail behavior. Shareable results matter because release approval cannot depend on the original author being online. Repeatable execution matters because the whole point of the process is to remove ambiguity before traffic hits production.
This is where LoadTester’s design philosophy is more aligned with DevOps and SRE needs. The goal is not just to run a test. The goal is to turn a test into a reusable release-quality artifact: define the scenario, execute it consistently, compare it to prior runs, enforce performance expectations, and make the outcome obvious to the rest of the team.
That operational emphasis is especially useful for services with multiple dependencies. Consider a typical ecommerce or SaaS request path: CDN, edge auth, API gateway, application service, cache, database, payment or third-party integration. Under load, the question is rarely “can one endpoint answer requests?” The question is “can this service path survive realistic concurrency without breaking our reliability expectations?” A tool that makes recurring validation easier will usually outperform a tool that merely makes script authoring pleasant.
If your team wants a credible release gate rather than a clever test script, LoadTester is usually the better fit.
How DevOps teams should evaluate an Artillery replacement
The best evaluation framework is practical. Do not ask which tool looks most modern or which community is loudest. Ask how each option behaves under the pressures your team actually faces.
Start with scenario ownership. Who writes the tests today, and who needs to consume the results tomorrow? If authors and readers are different groups, favor a tool that optimizes readability and repeatability instead of only authorship.
Then test CI/CD behavior. Put the tool into a real pipeline, not a demo branch. Can it fail a build for the right reasons? Are the artifacts useful? Can another engineer review the output quickly? If the answer depends on custom scripts and undocumented conventions, the workflow is weaker than it looks.
Next, test comparison quality. Run a baseline build and a modified build. Ask whether the system makes the regression obvious. A good result view should help you answer: what changed, by how much, and is it likely operationally significant? If that analysis still requires manual spreadsheet work, the tool is not doing enough of the job.
Also evaluate environment handling. Run the same test against staging on two different days. Can you tell what was different? Are test parameters, traffic phases, and threshold expectations visible? Performance investigations fail all the time because environment context was lost.
Finally, evaluate organizational survivability. Assume the engineer who set everything up leaves the team. Can someone else operate the workflow next month without archaeology? This is an underrated but brutally effective question. The best tool is often the one that leaves the least amount of custom process behind.
Migration plan: moving off Artillery without losing confidence
Switching tools should not create a blind spot in your reliability process. The safest approach is a staged migration with explicit comparison.
Step one is to inventory what your current Artillery tests are actually doing. Separate exploratory scripts from release-significant scenarios. In most teams, only a subset of the existing tests needs to become first-class recurring checks.
Step two is to define acceptance criteria in operational terms rather than tool-specific terms. For example: browse endpoint p95 under 300 ms at N requests per second, checkout flow error rate below 0.5 percent, or webhook ingestion sustained for 15 minutes without queue lag exceeding a threshold. This prevents the migration from becoming a syntax translation exercise instead of a reliability improvement.
Step three is to run both systems in parallel for a period. Use the old tests to preserve continuity, and the new workflow to validate that the same signals are visible more clearly. Parallel runs help surface environmental differences, hidden assumptions, and baseline mismatches before you retire the old process.
Step four is to attach the new checks to release events gradually. Start with informational runs, then warning-level gates, then hard blocking gates once the thresholds have been validated. This avoids creating organizational resistance through overly aggressive enforcement on day one.
Step five is to simplify aggressively. Once the new workflow proves itself, delete the custom glue that only existed to compensate for the old tool’s limitations. That is where the operational payoff finally appears. Migration is not complete until the incidental complexity has been removed.
Common mistakes teams make when replacing Artillery
The biggest mistake is choosing another script-first tool without addressing the actual workflow problem. Teams often move from one CLI to another, change the syntax, and discover that the baseline, reporting, and CI semantics are still largely homemade. That is not a real upgrade. It is a lateral move.
Another mistake is overfitting tests to the benchmark rather than the service objective. Developers sometimes optimize for prettier output or higher headline request rates instead of asking whether the scenario reflects production risk. An SRE-friendly workflow begins with user journeys, dependency behavior, and SLO relevance.
A third mistake is skipping threshold design. Without explicit performance expectations, migration just gives you new charts. Decide what constitutes failure before you automate gates. Otherwise teams will learn to ignore the signal.
A fourth mistake is treating staging as if it were inherently trustworthy. If the environment is noisy, undersized, or behaviorally different from production, better tooling will not save you from weak experimental design. The migration should include environment discipline.
The last mistake is keeping every old test forever. Performance programs get healthier when they focus on critical paths and meaningful release risks. A smaller set of high-trust recurring checks is better than a large pile of brittle scripts that nobody believes.
How this comparison was evaluated
For this Artillery alternative page, we compared the tools around a team-owned API regression workflow: authoring a scenario, adding assertions, running it on demand and from CI, sharing the outcome, and keeping enough history to recognize performance drift.
Artillery remains attractive for config-as-code teams and JavaScript extension workflows. LoadTester is the stronger fit when the evaluation goal is repeatable HTTP/API validation with less custom reporting and fewer repo-specific conventions.
When you should stay on Artillery
- Your tests need to live as YAML/JS in the same repo as the app and be reviewed as part of normal PRs.
- You're using Artillery's plugin ecosystem (Socket.IO, custom protocols) in ways no UI-driven tool can replicate.
- Your runners must execute inside a private network with no outbound calls, and the tooling can't be a SaaS.
Final recommendation
If you are a solo engineer or a small team doing mostly exploratory API testing, Artillery may still be enough. It is competent, flexible, and pleasant for the right kind of work.
If you are a DevOps, SRE, or platform-minded team trying to operationalize performance checks across releases, environments, and multiple engineers, the better Artillery alternative is usually the one that improves the workflow around the test rather than the syntax of the test. In that category, LoadTester is the stronger choice because it better supports repeatability, threshold enforcement, historical comparison, and team-readable results.
The honest framing is simple: Artillery is often good at authoring tests. Mature teams eventually need something better at operating them.
FAQ
Is Artillery still a good choice for API load testing?
Yes. It is still a valid choice for developer-led API tests, especially when the goal is quick experimentation. Teams usually replace it when they need stronger baselines, clearer results, and better CI/CD behavior.
What usually pushes SRE or DevOps teams to leave Artillery?
The operational overhead around the tool. Common triggers are manual comparisons, weak sharing of results, inconsistent environment handling, and custom pipeline glue that becomes hard to maintain.
Should I replace Artillery with another open-source CLI tool?
Only if the main problem is specific to Artillery itself. If your real pain is workflow, reporting, and release gating, moving to another CLI often preserves the same structural issues.
When is LoadTester the better alternative?
When performance testing is no longer a one-off engineer task and has become part of release confidence. That is where repeatable runs, thresholds, historical comparisons, and readable results matter most.