Performance Testing vs Load Testing vs Stress Testing
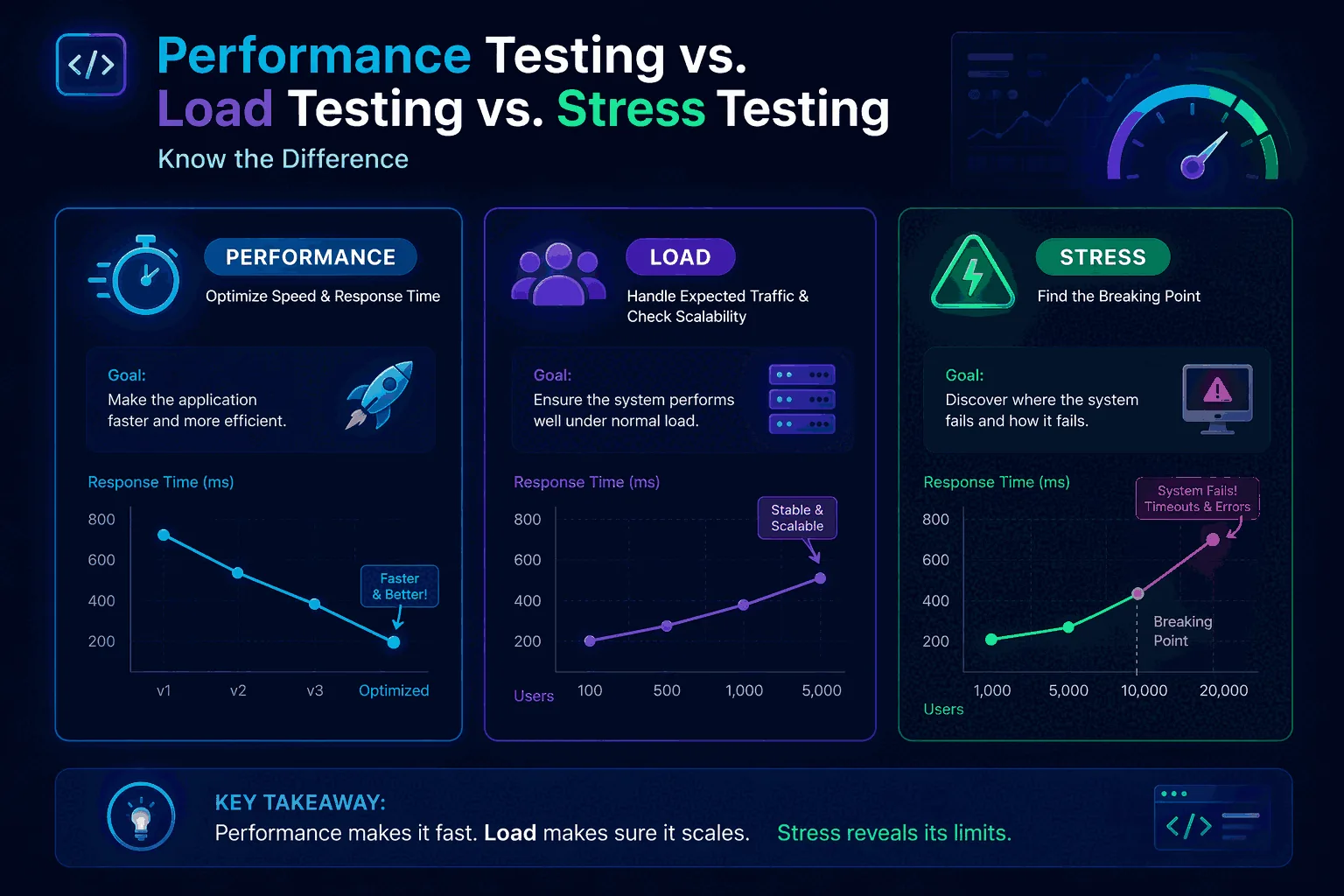
The terms get used interchangeably in standups all the time. The fast answer is that load testing and stress testing are both kinds of performance testing — they're not alternatives to it. Performance testing is the umbrella; load and stress are two of the specific tests that live under it.
The reason this matters: when terminology is fuzzy, the test design ends up answering a question nobody asked. A "stress test" run at expected peak load tells you nothing about breaking points. A "performance test" that's actually one health-check ping at 50 RPS tells you the system is up — not that it's ready for launch day. Sorting out which test answers which question is most of the work.
For a step-by-step tutorial after this, see How to Load Test an API. For platform comparisons, Best Load Testing Tools (2026).
The short answer
The shortest useful answer is this:
- Performance testing is the umbrella category. It includes many kinds of tests used to understand speed, stability, scalability, and responsiveness.
- Load testing is one type of performance testing. It checks how the system behaves under expected or gradually increasing real-world traffic.
- Stress testing is another type of performance testing. It pushes the system beyond expected capacity to find the breaking point, failure behavior, and recovery behavior.
So if someone asks about the difference between load and performance testing, the simplest correct answer is that load testing is a subset of performance testing. And if someone asks about load testing vs stress testing, the answer is that both are subsets of performance testing but they are designed to answer different questions. Load testing is about normal or near-normal demand. Stress testing is about limits, failure, resilience, and recovery.
That short answer is accurate, but it is not enough to help teams make decisions. The rest of this article is about how those categories work in practice.
Why teams mix these terms up
Three reasons the terms get mixed up. Vendors write "performance testing" because it sounds comprehensive. Tools that support multiple test types make people refer to the tool instead of the test objective. And in delivery work, people use the nearest familiar word, which is why GitHub Actions jobs called stress-test are usually 60-second smoke load tests.
The fix is to anchor the term to the decision being made. "Can checkout handle the Black Friday peak we forecast?" — load test. "Where does it fail and how does it recover?" — stress test. "What's our overall capacity, latency, and stability picture under the four traffic shapes our system actually sees?" — performance testing program.
What performance testing actually means
Performance testing is the broad discipline of testing how a system behaves in terms of speed, responsiveness, stability, resource use, and scalability. It is not one test. It is a family of tests. The exact mix depends on the system, the risk, and the questions the team needs answered.
A useful way to think about performance testing is as a category of evidence. It helps you gather evidence about whether your application is fast enough, stable enough, and scalable enough for real usage. That evidence can come from many types of tests, including load testing, stress testing, spike testing, soak testing, endurance testing, and capacity testing. Some organizations use more categories than others, but the core idea stays the same: performance testing is the umbrella.
Because it is an umbrella term, performance testing is often where strategy discussions begin. A team may decide it needs performance testing before a launch, but then it still has to choose which specific test types make sense. Sometimes that means a baseline load test, a spike test for a marketing event, a short stress test to find obvious limits, and a recurring smoke test in CI/CD. Sometimes it means only a small number of targeted load tests on the most important endpoints. The right answer depends on the system and the risk profile.
That broader framing is important because it prevents false confidence. If a team says “we did performance testing” but only ran one light load test against a health endpoint, it has not actually learned much about the whole system. The category should force people to ask what kinds of evidence are missing.
What load testing actually means
Load testing is the practice of testing how the system behaves under an expected or planned level of demand. That demand might represent average traffic, peak traffic, or a realistic growth scenario you expect the system to handle. The goal is not to destroy the system. The goal is to validate that the system behaves acceptably under the load it is supposed to absorb.
In day-to-day software work, load testing is usually the most useful performance test type because it maps directly to operational decisions. Can the API handle the daily peak? Can the login flow survive a product launch? Can the checkout service maintain a healthy p95 under the load marketing is forecasting? Can the queue workers keep up when concurrency increases? These are load testing questions.
Load testing is also where teams build repeatable release checks. A run can be compared across builds, tied to thresholds, automated in CI/CD, and scheduled for recurring validation. That is one reason load testing is often the first serious performance practice a team adopts. It is concrete, repeatable, and useful even without a giant performance engineering program.
If you want a practical implementation guide, the full walkthrough in How to Load Test an API covers traffic models, thresholds, result analysis, and CI/CD integration in much more detail. But conceptually, the most important point here is simple: load testing is about expected demand and acceptable behavior under that demand.
What stress testing actually means
Stress testing is the practice of pushing a system beyond the range of traffic or concurrency it is expected to handle, specifically to find its limits and observe how it fails. Stress testing is not just “more load testing.” Its purpose is different. It asks where the breaking point is, what symptoms appear first, whether the failure mode is graceful or chaotic, and how recovery behaves once the pressure is removed.
That makes stress testing especially useful when you need to understand resilience rather than just normal operating capacity. What happens if a product goes unexpectedly viral? What happens if a queue backlog explodes? What happens if a dependency gets slower while traffic is still rising? Does the application shed load cleanly? Do users get useful errors? Does the system recover automatically, or does it require manual intervention? Those are classic stress testing questions.
Stress testing can be very valuable, but it is also easier to misuse. Teams sometimes run an extreme scenario in staging, see that the system eventually failed, and conclude that the application is weak. That may be true, but the finding may also be meaningless if the scenario was unrealistic or if the environment was nowhere near production parity. The goal of stress testing is not to theatrically “break the app.” The goal is to learn something useful about margins, failure modes, and recovery.
If you want a broader stress-testing angle, stay with this guide and the linked planning resources. It is worth keeping the distinction clear though: stress testing is not a replacement for routine load testing. It is a different tool for a different question.
The difference between load and performance testing
The phrase difference between load and performance testing shows up in search because people sense that the two terms are related but not identical. The cleanest way to explain the difference is through scope.
Performance testing is the larger practice of evaluating system speed, stability, responsiveness, and scalability through different types of tests. Load testing is one specific test type inside that practice. If performance testing is the category, load testing is one method within it.
That means the difference is not about whether one is “better” than the other. It is about precision. Saying “we need performance testing” is like saying “we need analytics.” It points to a broad area of work. Saying “we need load testing” is more specific. It says you want to validate how the system behaves under expected demand.
The practical risk is that broad language can hide missing work. A team that says “we ran performance tests” may have performed a single load test and nothing else. Another team may have run several useful load tests but still missed a necessary stress scenario. That is why precise terminology matters: it reveals what evidence you do and do not have.
| Question | Performance testing | Load testing |
|---|---|---|
| What is it? | Umbrella category for evaluating responsiveness, speed, stability, and scalability. | A subset of performance testing focused on expected or planned traffic levels. |
| Main goal | Build a broad understanding of system performance characteristics. | Validate that the system behaves acceptably under normal or forecast traffic. |
| Typical outputs | Several test types, baselines, capacity insights, bottleneck analysis, and operational guidance. | Latency, throughput, error rate, threshold results, regression comparisons, and release confidence. |
| Best use case | Broader performance strategy and coverage. | Routine release validation and production-like capacity checks. |
When teams ask which one they should “do,” the answer is usually both. They should adopt performance testing as a practice and load testing as one of the primary test types within that practice.
Load testing vs stress testing
The comparison between load testing vs stress testing is different because these are sibling categories rather than category versus subset. Both live under performance testing, but they serve different purposes.
Load testing checks whether the system performs well enough at expected traffic levels. Stress testing explores what happens after the system moves beyond those levels. Load testing is about confidence within the operating range. Stress testing is about learning what happens beyond the operating range.
That sounds simple, but the implications are significant. In a load test, you usually care about whether key metrics remain within acceptable thresholds. In a stress test, you usually care about where thresholds start to break, how the application fails, whether it degrades gracefully, and whether it recovers cleanly when the pressure drops. In a load test, success might mean “p95 stayed below 500 ms and error rate stayed below 1%.” In a stress test, success might mean “the system shed traffic without total collapse, recovered automatically after the peak, and surfaced clear signals about where the bottleneck appeared.”
| Dimension | Load testing | Stress testing |
|---|---|---|
| Traffic level | Expected or planned peak levels. | Beyond expected capacity. |
| Goal | Validate normal operational readiness. | Find breaking points and observe failure behavior. |
| Pass criteria | Usually defined by thresholds for latency, throughput, and error rate. | Usually defined by insights about limits, graceful degradation, and recovery. |
| When to run | Before releases, after changes, on a schedule, or in CI/CD. | Before major launches, architecture reviews, resilience reviews, or capacity planning exercises. |
| Risk | Relatively low when run responsibly. | Higher, especially if environments or dependencies are not isolated properly. |
One of the best ways to think about this is to imagine a road. Load testing asks whether the car stays stable at normal highway speeds. Stress testing asks what happens when you go faster than you ever intend to drive. Both are useful, but they answer different questions and should not be confused.
Where spike testing, soak testing, and capacity testing fit
It is also useful to mention a few adjacent categories because they help explain the shape of the performance testing umbrella. Spike testing examines what happens when traffic rises sharply and suddenly. It is helpful for launch events, batch jobs, or marketing moments where demand can jump rather than climb gradually. Soak testing or endurance testing looks at behavior over a long duration to find memory leaks, resource exhaustion, and performance drift. Capacity testing is often used to determine how much load the system can sustain while still meeting service targets.
These categories matter because they show why the umbrella concept is useful. If your whole “performance testing” strategy consists only of one short load test, you may completely miss a system that behaves well for 10 minutes but degrades over two hours, or a system that survives gradual ramp-up but struggles with sudden spikes. The categories are not there to make testing sound more complicated. They are there to make the questions more explicit.
For most teams, the right initial mix is still simple: one or two well-designed load tests, one optional spike or stress scenario where justified, and recurring smoke coverage for critical flows. Complexity should be earned, not assumed.
Which one should you use and when?
The easiest way to choose is to map the test type to the decision you need to make.
Use load testing when...
- You need release confidence for critical APIs or flows.
- You want to validate expected traffic from a campaign, launch, or customer growth.
- You need recurring, comparable runs with thresholds.
- You want to catch regressions in CI/CD or on a schedule.
Use stress testing when...
- You need to understand the breaking point of a service.
- You want to observe failure modes and degradation behavior.
- You are doing resilience planning or capacity planning.
- You need to know how recovery behaves after overload.
Performance testing, as the umbrella, should guide the whole program. Load testing and stress testing are the specific tools within that program. If a team has limited time, load testing is often the best first investment because it supports repeatable operational decisions. Stress testing usually comes next when the team needs resilience insight, not just readiness insight.
This is also where planning matters. A load testing strategy helps you decide which flows need recurring load validation, which ones need occasional stress scenarios, and which metrics should determine whether a release is safe. Without that plan, teams tend to either do too little or do the wrong kind of test at the wrong time.
What to measure in all three cases
Regardless of the category, there are a handful of metrics that matter almost every time: latency percentiles, throughput, error rate, saturation indicators, and recovery behavior. The difference is not whether you measure them. The difference is how you interpret them for the purpose of the test.
Latency matters because averages can hide pain. In a release-oriented load test, p95 and p99 are usually more useful than the average because they tell you what slower users are experiencing. In a stress test, rising tail latency can help reveal the first stages of system strain even before hard failures dominate the chart.
Throughput matters because it tells you how much useful work the system handled. In a load test, it helps you validate capacity relative to the demand you expect. In a stress test, it helps you see where the system stops scaling linearly and where it starts flattening out or collapsing.
Error rate matters because it tells you whether the system stayed usable. In a normal load test, error budgets and release thresholds are often the main pass/fail criteria. In a stress test, errors are expected eventually, but the pattern matters. Do they appear gradually or suddenly? Are they clean, informative failures or chaotic timeouts?
Saturation signals matter because they explain why results changed. CPU, memory, thread pools, connection pools, queue depth, cache hit rates, and database behavior often tell the real story behind the external metrics. Good performance work uses application-facing metrics and infrastructure-facing metrics together.
Recovery behavior matters most in stress testing, but it is useful everywhere. If a burst of load causes a backlog or a temporary slowdown, how long does the system take to normalize? A system that survives overload but recovers slowly may still create real customer pain.
How the scenarios differ
One of the easiest ways to understand the difference between performance testing, load testing, and stress testing is to compare the scenarios you would design for each.
For a load test, you usually pick one or more realistic traffic patterns and run them at or near expected levels. You may ramp up gradually to a target number of virtual users or a target requests-per-second rate. You may run for 10, 20, or 60 minutes. You define thresholds for p95, throughput, and error rate, then compare the result with earlier baselines. This kind of test is stable, repeatable, and operationally useful.
For a stress test, you usually go past those expected levels deliberately. You may step demand higher every few minutes. You may keep rising until latency becomes unacceptable, errors spike, or a major resource saturates. The point is not simply to produce a red chart. The point is to identify where the system bends, breaks, or recovers.
For performance testing at the broader program level, the scenario design question is not “which one scenario?” but “which set of scenarios gives us enough evidence?” That is the strategic perspective. A single product might need a baseline load test, a spike test for launch-day demand, and an occasional stress test for resilience reviews. Another product might only need stable recurring load tests. The correct mix depends on context.
A realistic release workflow
To make the distinction concrete, imagine a SaaS team preparing a significant release for a public API.
The team starts with a recurring load test against login, search, and checkout-like API flows. These runs already exist in the system because they are executed on a schedule. They compare the new build to the previous baseline. p95 latency on one endpoint is slightly worse, but still within threshold. Error rate stays near zero. Throughput remains healthy. That gives the team confidence that expected traffic is still safe.
Next, because the release includes a major caching change, the team runs a short stress test in a safe environment to see how the system behaves past forecast load. They keep increasing request rate beyond the launch expectation. They discover that once a certain threshold is crossed, a downstream dependency becomes the bottleneck and the API begins timing out rather than returning clean 429 or 503 responses. That finding does not block the release, because the launch is not expected to hit that level, but it creates a clear follow-up item for resilience work.
From the broader performance testing perspective, both tests are valuable and complementary. One validates operational readiness. The other reveals a resilience weakness. Together they produce better decision-making than either would alone.
Common mistakes teams make
One common mistake is assuming that one successful load test means performance testing is “done.” It is not. A single run tells you something, but not everything. Another common mistake is using the word stress test for any scenario with high traffic, even when the traffic is still within expected bounds. That sounds minor, but it leads stakeholders to think the team already understands breaking behavior when it does not.
A third mistake is running unrealistic scenarios. Teams sometimes create synthetic tests that hit only one easy endpoint, use no authentication, or avoid realistic dependencies. The result may look clean, but it does not represent the system users actually exercise. A fourth mistake is ignoring comparisons over time. A performance result is much more useful when you know whether it is better or worse than last week. That is one reason workflows like continuous load testing are so valuable: they make comparison part of the habit instead of an afterthought.
Another major mistake is forgetting to define what “good enough” means. A load test without thresholds is just an experiment. A good test plan states what pass and fail look like before the run begins.
How LoadTester fits into the picture
LoadTester is built for the load-testing slice of this spectrum, not all of it. Saved HTTP scenarios, RPS or VU traffic models, threshold-based pass/fail, run-to-run comparison, scheduling, and a CI/CD API. That covers the recurring "is this release safe to ship" question well; it does not cover open-ended stress investigation as cleanly as a custom k6 script does, and we don't pretend it does.
For tool comparisons: Best Load Testing Tools (2026), LoadTester vs k6, LoadTester vs JMeter.
In practice, many teams adopt a simple pattern:
- Use LoadTester for recurring load tests on critical endpoints and user flows.
- Use comparisons and thresholds to protect releases.
- Schedule runs for ongoing validation.
- Add a few deeper exploratory scenarios when architecture or traffic risk justifies them.
That approach is realistic, useful, and much easier to sustain than a giant performance engineering program that only runs twice a year.
How to talk about results with stakeholders
One underrated part of this topic is communication. Stakeholders often hear the words performance, load, and stress and assume they all mean roughly the same thing. That creates confusion when engineers try to explain what was actually tested. A simple communication pattern helps:
- For load tests, explain what expected traffic level was simulated and whether user-facing thresholds were met.
- For stress tests, explain where the system started to degrade or fail and what the recovery behavior looked like.
- For performance testing as a program, explain which test types were run and what risks remain uncovered.
This makes reports more honest and more useful. Instead of saying “performance testing passed,” you can say “critical API load tests met the release thresholds, but the system still has an ungraceful failure mode beyond 2.5× forecast demand.” That is the kind of statement leadership can act on.
What page should you read next?
If this article answered the terminology question, the next step depends on what you need to do next. If you want to understand the broader discipline, read What Is Load Testing?. If you need a practical implementation guide, read How to Load Test an API. If you need to design a repeatable practice for your team, read Load Testing Strategy. If you want performance checks to happen regularly instead of occasionally, read Continuous Load Testing.
That learning path matters because performance testing topics should not be treated as isolated definitions. Each concept should lead naturally to the next practical step in the workflow: choosing a scenario, defining thresholds, running the test, and interpreting the result.
Final thoughts
The difference between these terms is simple once you anchor them to the question being asked. Performance testing is the broad practice. Load testing validates expected demand. Stress testing explores behavior beyond expected demand. When teams keep those distinctions clear, they choose better scenarios, set better expectations, and make better release decisions.
The more important lesson, though, is that you do not need to pick only one forever. Mature teams use several types of tests at different moments for different reasons. They use load testing to protect critical flows, stress testing to understand resilience, and a broader performance testing strategy to decide what evidence is still missing. That is how the terminology stops being academic and starts being operational.
Frequently asked questions
What is the practical difference between performance, load, and stress testing?
Performance testing is the umbrella term for measuring how a system behaves under any workload. Load testing measures behavior under expected production load — the goal is 'does it meet the SLO?'. Stress testing pushes well past expected load to find the breaking point and the failure mode — the goal is 'where does it break and how?'. Each answers a different operational question.
Which one should you run first for a new service?
Start with a basic load test at expected peak production traffic. That answers the most common operational question — 'will this hold up on launch day?' — with the least setup. Stress testing comes next, once you know the service handles expected load and you want to understand its breaking point. Soak testing (sustained load over hours) is the third layer, useful for catching memory leaks and connection-pool exhaustion.
Are these tests separate runs or different views of the same run?
On modern platforms, often the same run with different traffic shapes. A ramping load test that climbs from 0 to 200% of expected peak gives you the load picture (at the planned peak), the stress picture (at 150-200%), and the saturation curve in between. Soak behavior still requires a separate sustained run because the failure modes only appear over hours, not minutes.